library(mvtnorm)
library(MASS)
library(dplyr)
library(ggplot2)
library(plot3D)
library(gplots)
library(tidyverse)
library(plotly)
library(tidyverse)
library(scales)
library(factoextra)
library(NbClust)Clustering
1 L’article
Ce fichier Quarto utilise cet article Flynt et Dean (2016), l’objectif est de reproduire les résultats obtenus sur le sujet du clustering. Dans cette étude, on explore les méthodes de clustering en se basant sur des données simulées, en ayant pour objectif de reconstituer le clustering avec des méthodes statistiques.
2 Génération des données simulées
2.0.1 Importation des packages
2.0.1.0.1 Répartition des points simulés
set.seed(288)
# Creating continuous variables
pi = c(0.3, 0.4, 0.3)
mu = matrix(c(0, 0, 3, 5, 0, 6), 2, 3, byrow=FALSE) # Définition des moyennes des groupes 2 par 2
Sigma.sph = diag(c(1, 1))
Sigma.ell = matrix(c(2, 1.3, 1.3, 1),2, 2, byrow=TRUE)
cl = sample(c(1, 2, 3), 600, T, pi)
X = matrix(0, 600, 2)
for(i in 1:600)
{
ifelse(cl[i] == 3, X[i,]<-rmvnorm(1, mu[,3], Sigma.ell), X[i,]<-rmvnorm(1, mu[,cl[i]], Sigma.sph))
}
eqscplot(X, col = "gray1", pch = 18)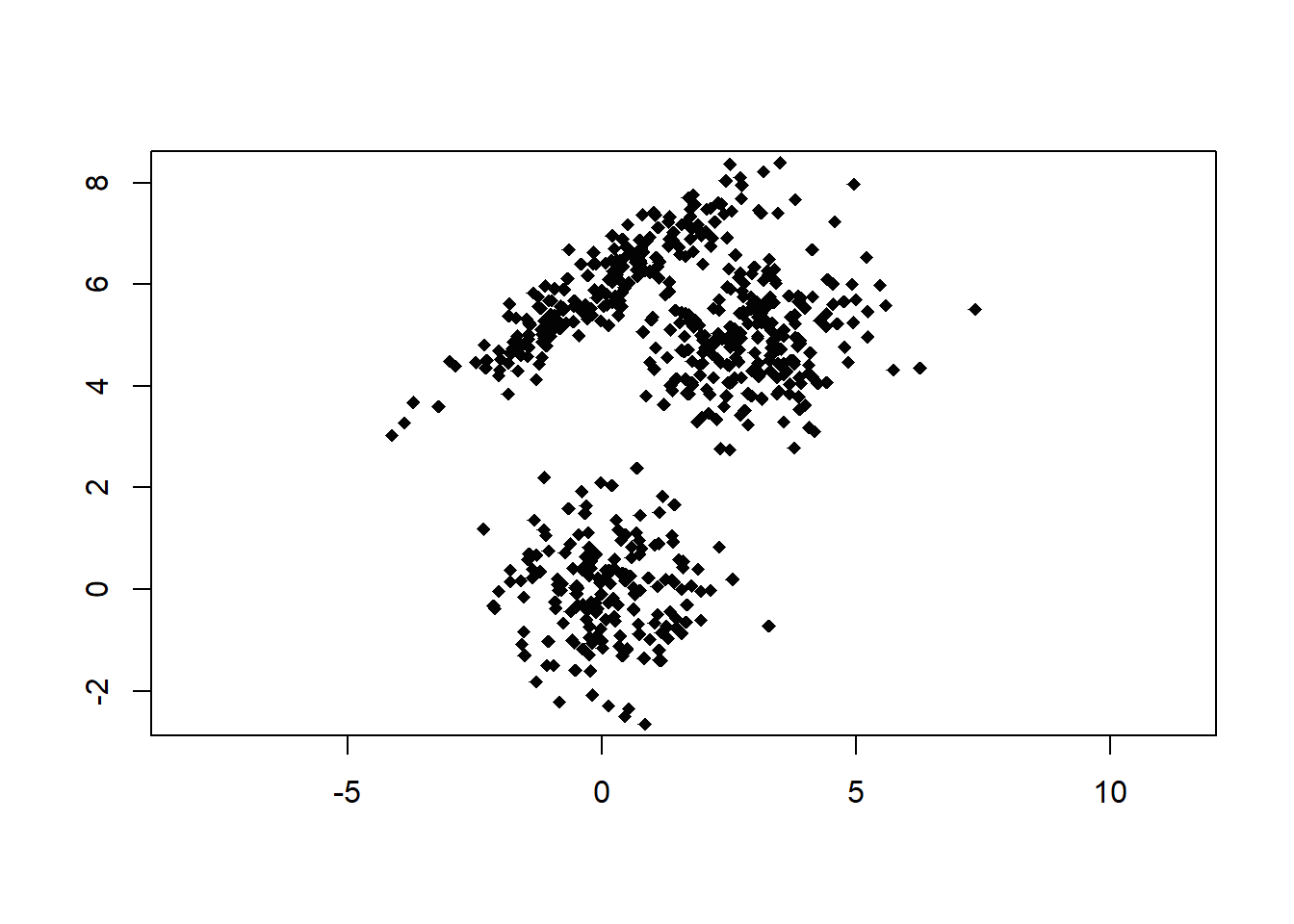
2.0.1.0.2 Répartition des points simulés - version ggplot
X %>% as_tibble() %>% ggplot(aes(x = V1, y= V2)) +
geom_point() + theme_minimal() + ggtitle("Répartition des points simulés en 2 dimensions")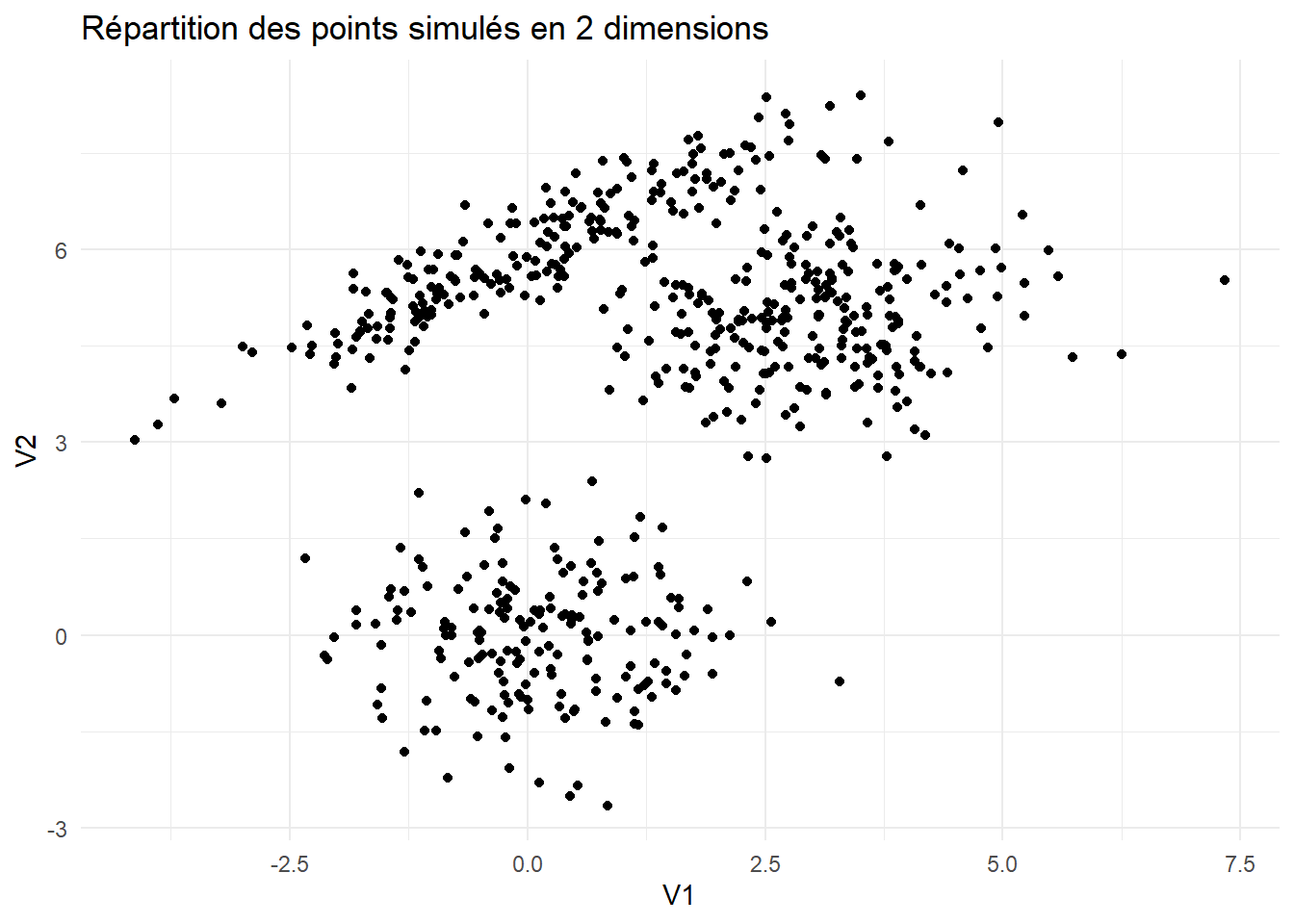
2.0.1.0.3 Représentation en 3D de l’histogramme de la loi normale bivariée
# 1. Créer les "bins" (les classes) pour les deux colonnes
x_bins <- cut(X[,1], breaks = 10)
y_bins <- cut(X[,2], breaks = 10)
# 2. Créer la table de fréquences (la matrice Z)
z_matrix <- table(x_bins, y_bins)
# 3. Définir les coordonnées des centres des barres
x_coords <- seq(min(X[,1]), max(X[,1]), length.out = nrow(z_matrix))
y_coords <- seq(min(X[,2]), max(X[,2]), length.out = ncol(z_matrix))
hist3D(x = x_coords, y = y_coords, z = z_matrix,
border = "black",
colkey = TRUE,
lighting = TRUE,
main = "Représentation 3D de la loi normale bivariée",
xlab = "x",
ylab = "y",
zlab = "Fréquence",
phi = 50, theta = -30) # Angles de vue
2.0.1.0.4 Répartition des individus
Groupe 1
On a 177 noirs (29,5%), 237 rouges (39,5%), 186 vert (31%).
On est dans une loi normale bivariée, de paramètre (Espérance, Matrice variance-covariance). De moyenne = (0,0) et de matrice variance covariance = marice identité :
diag(2) [,1] [,2]
[1,] 1 0
[2,] 0 1Groupe 2
On a une moyenne (3,5)
Groupe 3
On a une moyenne (0,6), et une matrice (2, 1.3, 1.3, 1)
prop.table(table(cl))cl
1 2 3
0.295 0.395 0.310 2.0.2 Représentation des données simulées en fonction de leur groupe
as_tibble(X) %>% ggplot(aes(x = V1, y=V2)) + geom_point(color = cl) + theme_minimal() + ggtitle("Représentation des variables continues en fonction des groupes prédéfinis") -> graph1
graph1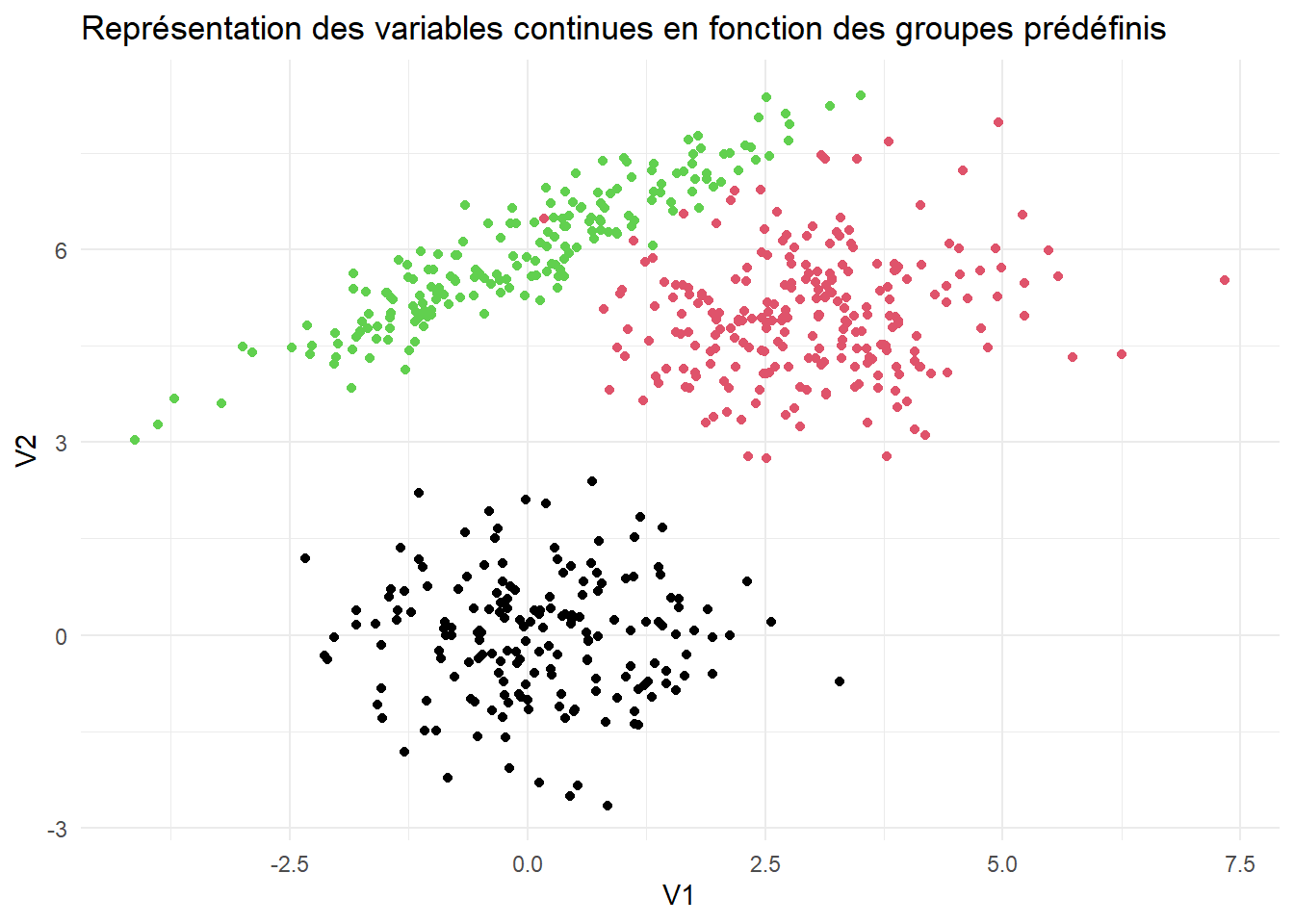
2.1 Création des variables discrètes
c1 : il utilise rbinom pour générer 600 chiffres avec une proba de succès de 0.5, +1 pour mettre les valeurs à 1 ou 2
c2 : si la couleur du point est noir alors on applique une proba plus importante au succès 1 sinon on applique une proba plus importante au succès 2.
# Creating discrete variables
# Note for poLCA and clustMD, coding must start at 1.
# Uniform prob. of success for all observations (success means a value of 2, whereas failure would be a value of 1)
c1 = rbinom(600, 1, .5) + 1
# Success more likely in red and green groups
c2 = NULL
for(i in 1:600){
ifelse(cl[i] == 1, c2[i]<-rbinom(1, 1, .1)+1, c2[i]<-rbinom(1, 1, .9)+1)
}
# More likely to be a 1 in black, a 2 in red and a 3 in green
c3 = NULL
for(i in 1:600){
if(cl[i] == 1) c3[i] = sample(1:3, 1, prob = c(.6, .2, .2))
if(cl[i] == 2) c3[i] = sample(1:3, 1, prob = c(.1, .8, .1))
if(cl[i] == 3) c3[i] = sample(1:3, 1, prob = c(.1, .1, .8))
}
# Success more likely in red group
c4 = NULL
for(i in 1:600){
ifelse(cl[i] == 2, c4[i]<-rbinom(1, 1, .8)+1, c4[i]<-rbinom(1, 1, .2)+1)
}
# Merging the variables into our complete mixed-mode dataset, vars
vars = cbind(X, c1, c2, c3, c4)
head(vars) c1 c2 c3 c4
[1,] 1.6137555 4.6784541 1 2 2 2
[2,] 0.3135524 -0.3026124 2 1 2 1
[3,] 3.1383011 3.7670414 2 2 2 1
[4,] -1.5400580 -0.1531943 1 1 1 1
[5,] 2.5165331 4.8541686 1 2 2 1
[6,] 1.9779610 4.4491698 1 2 2 22.1.0.0.1 Fréquence des modalités dans chaque groupe et variable des données
df_plot <- vars[, 3:6] %>%
as_tibble() %>%
mutate(cl = as.factor(cl)) %>%
pivot_longer(cols = c(c1, c2, c3, c4), names_to = "groupe", values_to = "valeur") %>%
mutate(valeur = as.factor(valeur))
# Création du graphique style "publication"
ggplot(df_plot, aes(x = cl, fill = valeur)) +
# Barres 100% empilées, avec un léger contour pour bien les séparer si besoin
geom_bar(position = "fill", width = 0.8) +
# Séparation par groupe (c1, c2, c3, c4)
facet_grid(~ groupe) + scale_fill_manual(values = c("grey30", "grey65", "grey90"))+
theme_classic()+
ggtitle("Fréquence des modalités dans chaque groupe et variable des données")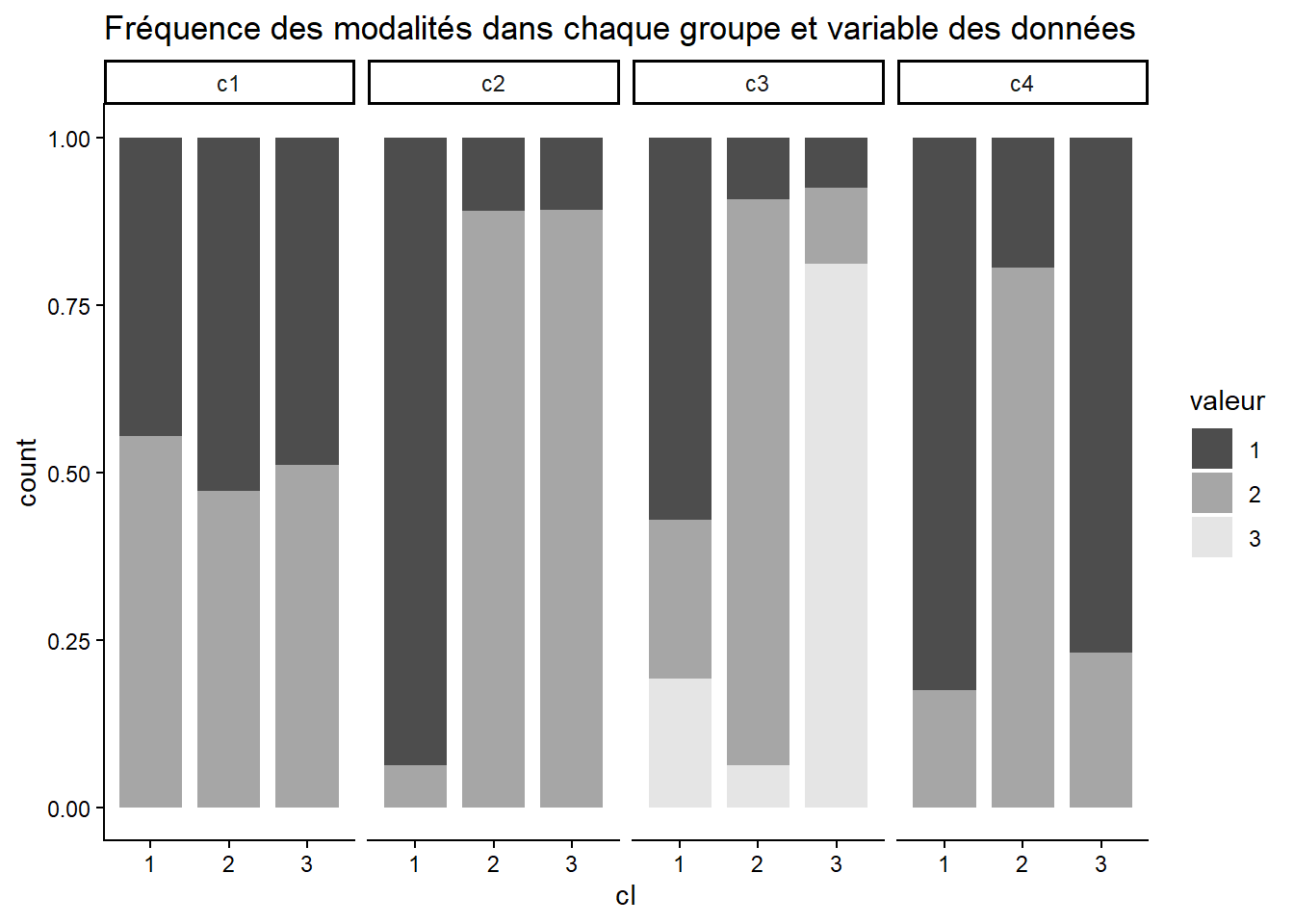
2.1.1 Application de la fonction k-means
On aurait pu explorer toutes les possiblités pour 2 clusters mais c’est impossible vu le nombre de possibilités
library(kStatistics)
nStirling2(600, 2)[1] 2.074758e+1802.2 Méthode du coude
# Elbow method
fviz_nbclust(vars [,1:2], kmeans, method = "wss") +
geom_vline(xintercept = 3, linetype = 2)+
labs(subtitle = "Méthode du coude - Nombre optimal de clusters") Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
ℹ Please use the `linewidth` argument instead.
ℹ The deprecated feature was likely used in the ggpubr package.
Please report the issue at <https://github.com/kassambara/ggpubr/issues>.Warning: The `size` argument of `element_rect()` is deprecated as of ggplot2 3.4.0.
ℹ Please use the `linewidth` argument instead.
ℹ The deprecated feature was likely used in the ggpubr package.
Please report the issue at <https://github.com/kassambara/ggpubr/issues>.Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
ℹ The deprecated feature was likely used in the ggpubr package.
Please report the issue at <https://github.com/kassambara/ggpubr/issues>.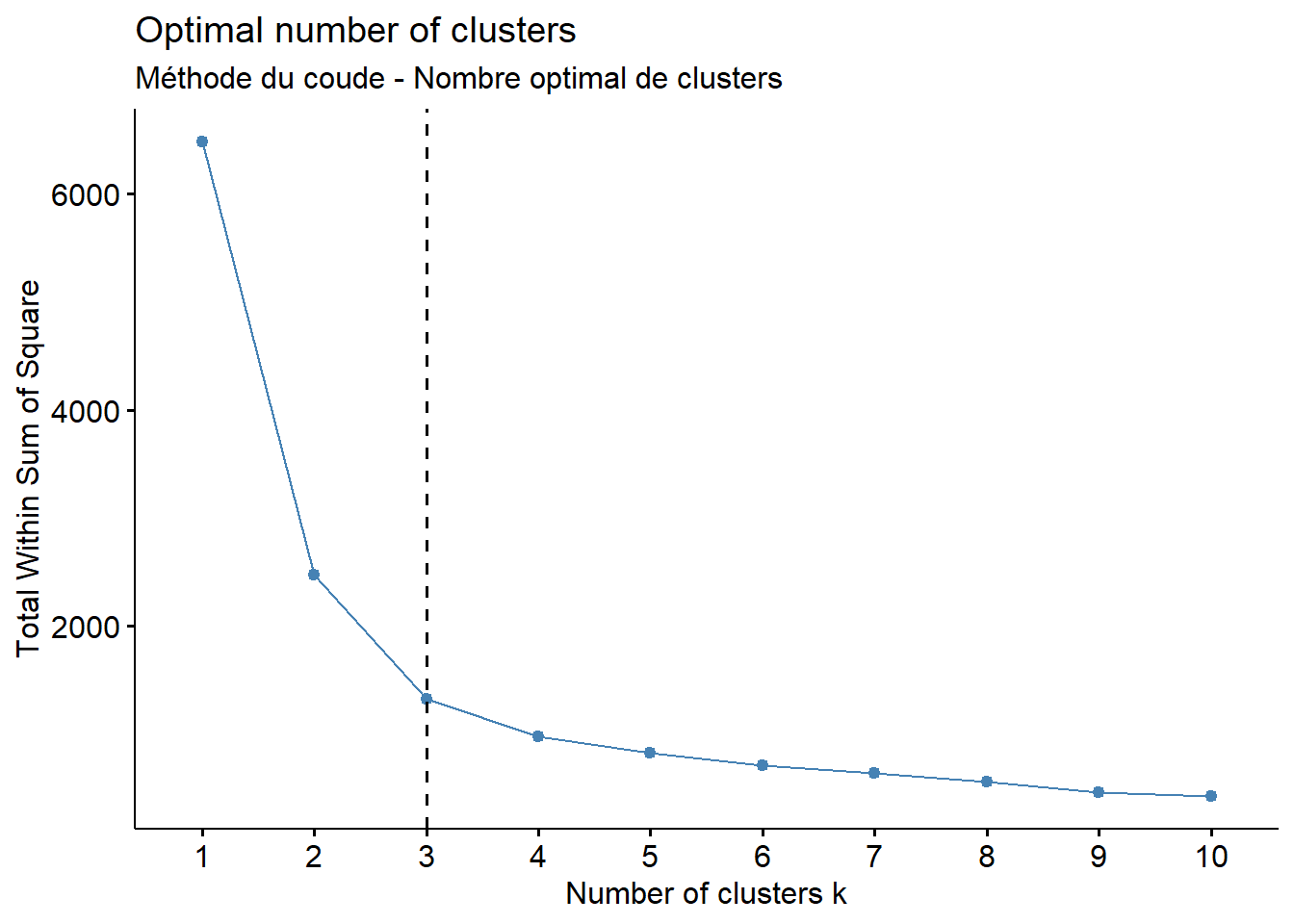
fviz_nbclust(vars [,1:2], kmeans, nstart = 25, method = "gap_stat", nboot = 50)+
labs(subtitle = "Gap statistic method") Warning: pas de convergence en 10 itérationsWarning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the factoextra package.
Please report the issue at <https://github.com/kassambara/factoextra/issues>.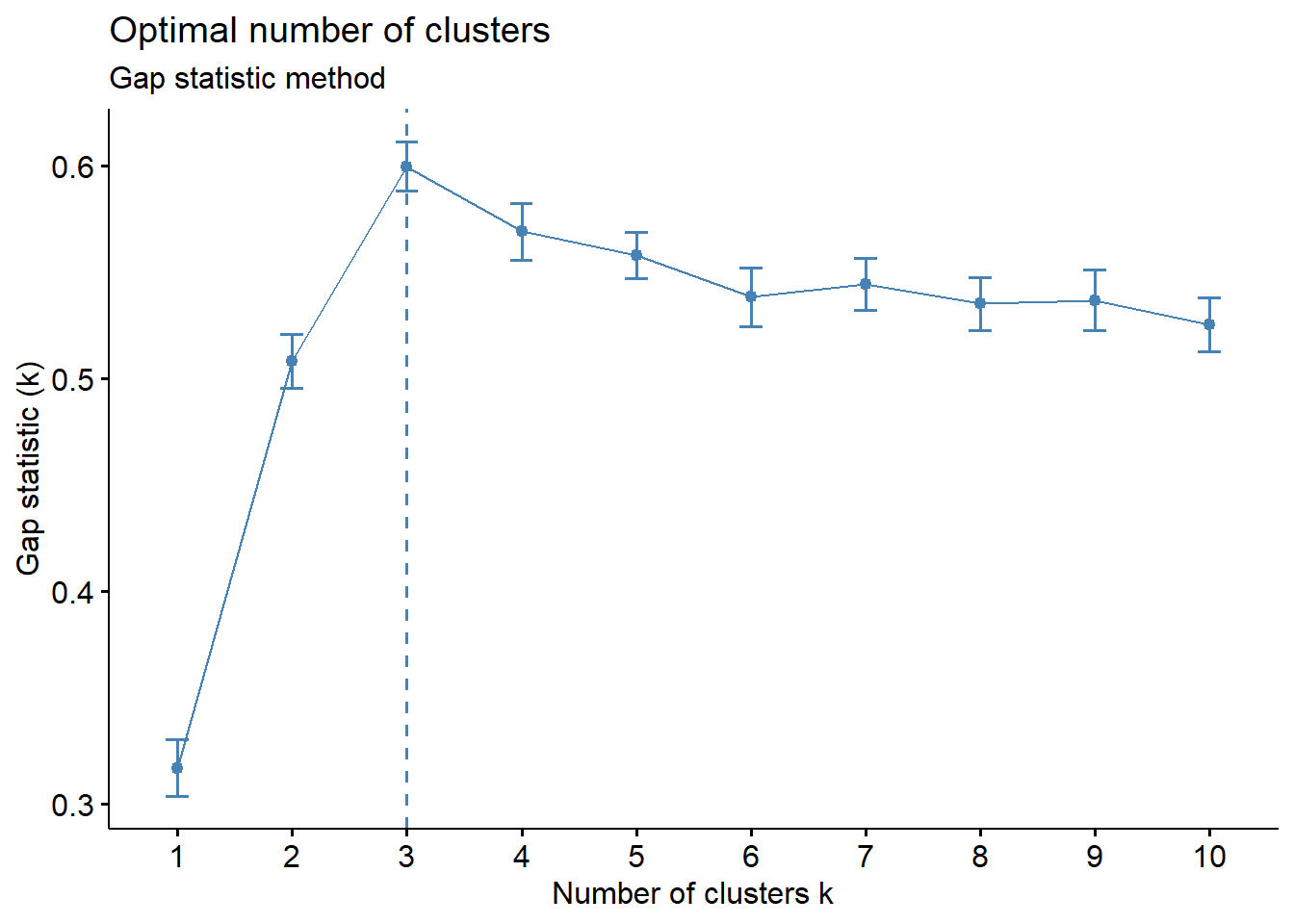
2.2.1 kmeans - Hartigan
Algo d’Hartigan
Description de l’algorithme d’Hartigam pour la méthode des kmeans.
\[ \begin{array}{l} \textbf{Algorithme de Hartigan-Wong (K-Means)} \\ \hline 1.\ \textbf{Initialisation : } \text{Distribuer chaque point dans un cluster au hasard.} \\ 2.\ \textbf{Calcul des centres : } \text{Calculer le centre moyen de chaque groupe formé.} \\ 3.\ \textbf{Boucle principale : } \text{Pour chaque point du jeu de données :} \\ \quad 4.\ \textbf{Test de transfert : } \text{Calculer si déplacer le point vers un autre groupe} \\ \quad \quad \text{rend l'ensemble des clusters plus compact.} \\ \quad 5.\ \textbf{Décision : } \text{Si le transfert améliore la qualité globale :} \\ \quad \quad 6.\ \textbf{Action : } \text{Déplacer le point dans le nouveau groupe immédiatement.} \\ \quad \quad 7.\ \textbf{Mise à jour : } \text{Recalculer aussitôt le centre du groupe qui a perdu} \\ \quad \quad \quad \text{le point et celui du groupe qui l'a gagné.} \\ 8.\ \textbf{Convergence : } \text{Recommencer l'étape 3 tant que des points bougent encore.} \\ \hline \end{array} \]
library(gridExtra)
cluster1 = kmeans (vars [,1:2], 1, nstart = 50)
cluster2 = kmeans (vars [,1:2], 2, nstart = 50) # dans k1 il y a 181 individus / dans k2 il y en a 419
cluster3 = kmeans (vars [,1:2], 3, nstart = 50)
library(tidyverse)
# Point moyen : moyenne_1 & moyenne_2
as_tibble(vars[,1:2]) %>% summarise(moyenne_1 = mean(V1),
moyenne_2 = mean(V2),
Variance = (var(V1) + var(V2)) * 599 # Somme des distances euclidiennes par rapport au p.m,
) # A tibble: 1 × 3
moyenne_1 moyenne_2 Variance
<dbl> <dbl> <dbl>
1 1.18 3.79 6481.as_tibble(X) %>% ggplot(aes(x = V1, y=V2)) + geom_point(color = cluster3$cluster) + theme_minimal() + ggtitle("Représentation des variables continues en fonction des groupes prédéfinis") -> graph2
grid.arrange(graph1, graph2, nrow = 1)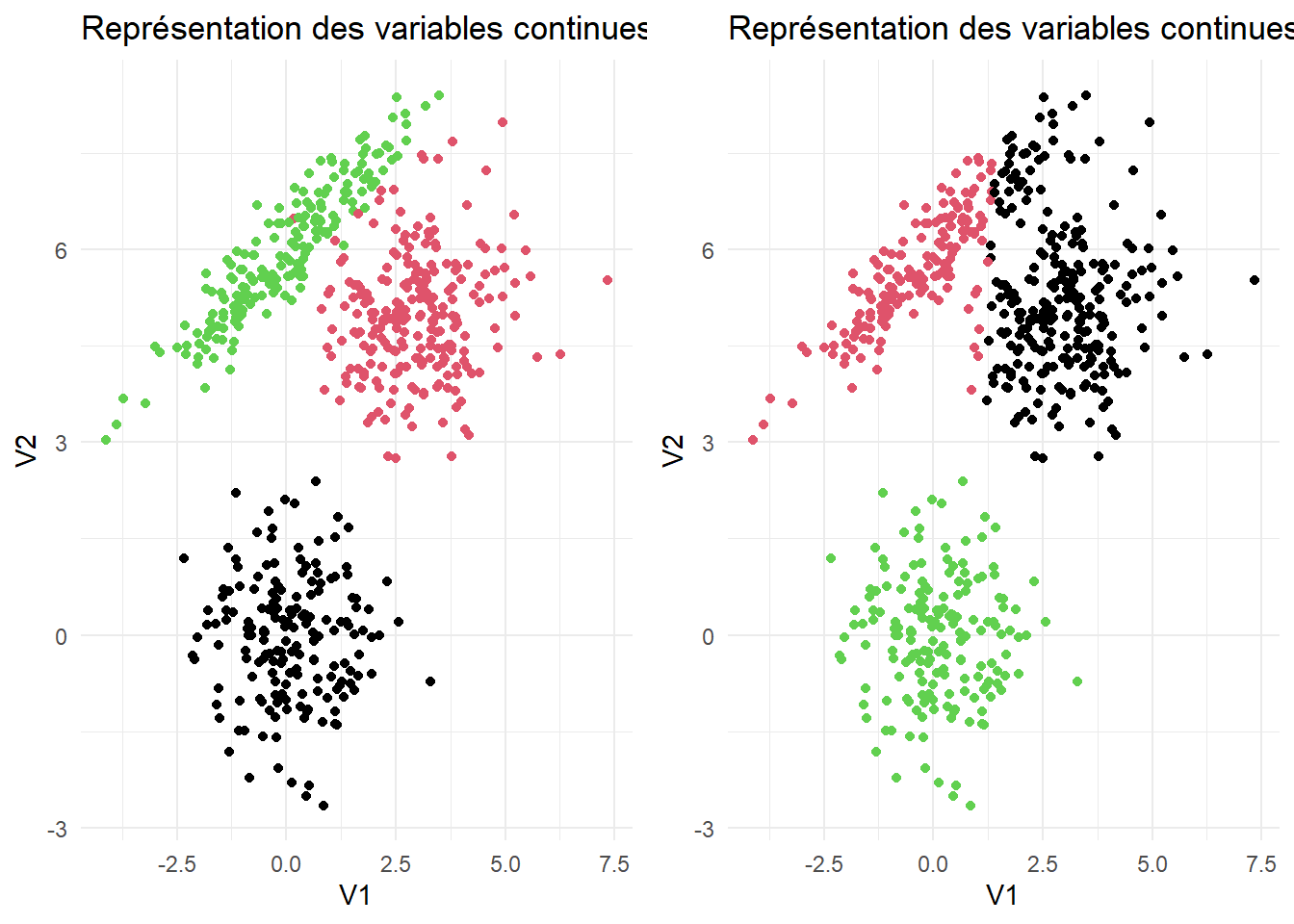
2.2.2 kmeans - Lloyd
Algo de Lloyd
\[ \begin{array}{l} \textbf{Algorithme de Lloyd (K-Means)} \\ \hline 1.\ \textbf{Initialisation : } \text{Choisir } k \text{ points au hasard pour être les centres.} \\ 2.\ \textbf{Boucle principale : } \textbf{Répéter tant qu'il y a des changements :} \\ \quad 3.\ \textbf{Assignation globale : } \text{Chaque point choisit le centre le plus} \\ \quad \quad \text{proche sans se soucier des autres points.} \\ \quad 4.\ \textbf{Attente : } \text{On attend que TOUS les points aient choisi leur groupe.} \\ \quad 5.\ \textbf{Mise à jour groupée : } \text{Une fois que tout le monde a fini de bouger,} \\ \quad \quad \text{on recalcule tous les nouveaux centres en une seule fois.} \\ 6.\ \textbf{Convergence : } \text{Arrêter quand les centres ne bougent plus d'une étape à l'autre.} \\ \hline \end{array} \]
cluster3_lloyd = kmeans (vars [,1:2], 3, nstart = 50, algorithm = "Lloyd")Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérations
Warning: pas de convergence en 10 itérationsas_tibble(X) %>% ggplot(aes(x = V1, y=V2)) + geom_point(color = cluster3_lloyd$cluster) + theme_minimal() + ggtitle("Représentation des variables continues en fonction des groupes prédéfinis")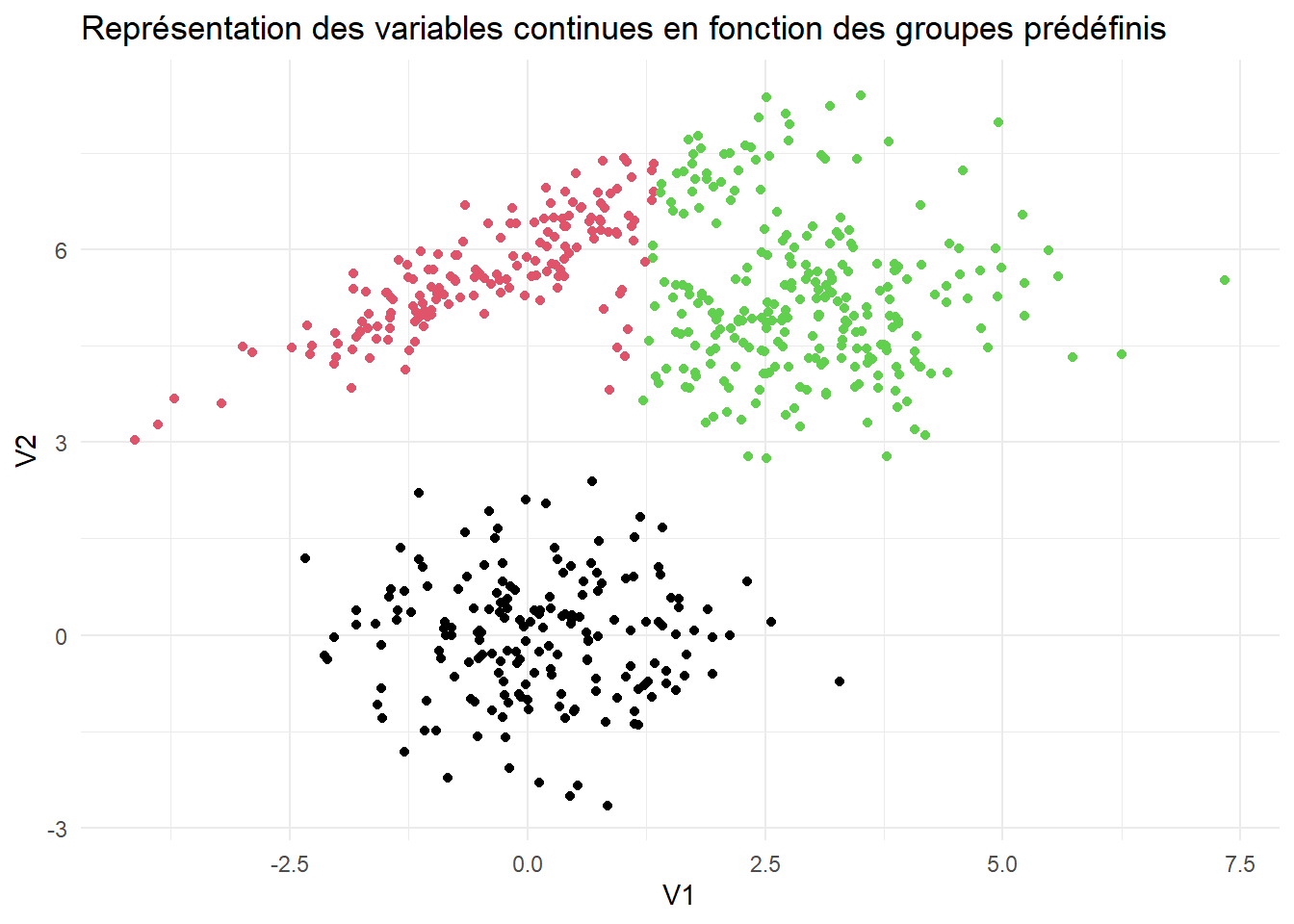
2.2.3 Représentation de l’enveloppe convexe
# 1. Combiner vos données, la couleur d'origine (cl) et les résultats du k-means
df <- as_tibble(X) %>%
mutate(
Couleur_Origine = cl,
# On extrait les affectations aux clusters de l'objet kmeans en facteur
Cluster_Kmeans = as.factor(cluster3_lloyd$cluster)
)
# 2. Calculer les points formant l'enveloppe convexe pour CHAQUE cluster k-means
# La fonction chull() renvoie les indices des points qui forment la bordure convexe
hulls <- df %>%
group_by(Cluster_Kmeans) %>%
slice(chull(V1, V2))
# 3. Créer le graphique combiné
ggplot(df, aes(x = V1, y = V2)) +
# Étape A : Tracer les enveloppes convexes (polygones) des K-means
# alpha = 0.3 permet de rendre la surface transparente pour voir les points
geom_polygon(data = hulls,
aes(fill = Cluster_Kmeans, group = Cluster_Kmeans),
alpha = 0.3, color = "black", linetype = "dashed") +
scale_fill_manual(values = c("#FAADAD", "#ADB4FA", "#ADFABA"))+
# Étape B : Tracer les points avec leurs couleurs d'origine (groupes prédéfinis)
geom_point(aes(color = factor(Couleur_Origine))) +
# Esthétique
theme_minimal() +
ggtitle("Représentation des variables continues en fonction des groupes prédéfinis\net enveloppes convexes des K-means") +
labs(fill = "Clusters K-means", color = "Groupes initiaux") 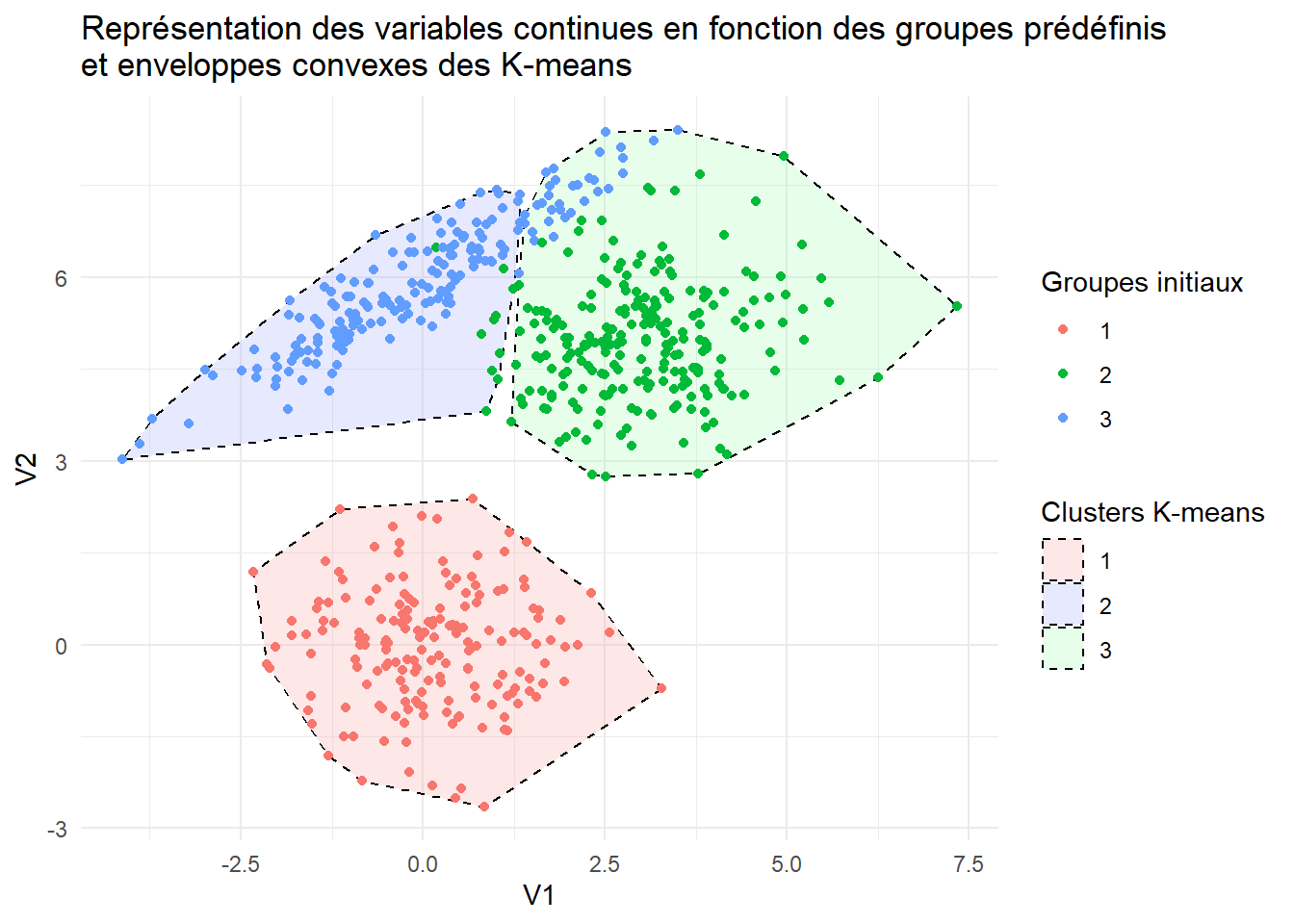
fviz_cluster(cluster3_lloyd,
data = vars[, 1:2],
ellipse.type = "convex",
geom = "point", # "point" évite d'afficher le numéro de chaque ligne
show.clust.cent = TRUE, # Affiche le centre des clusters (croix)
main = "Représentation des clusters K-means")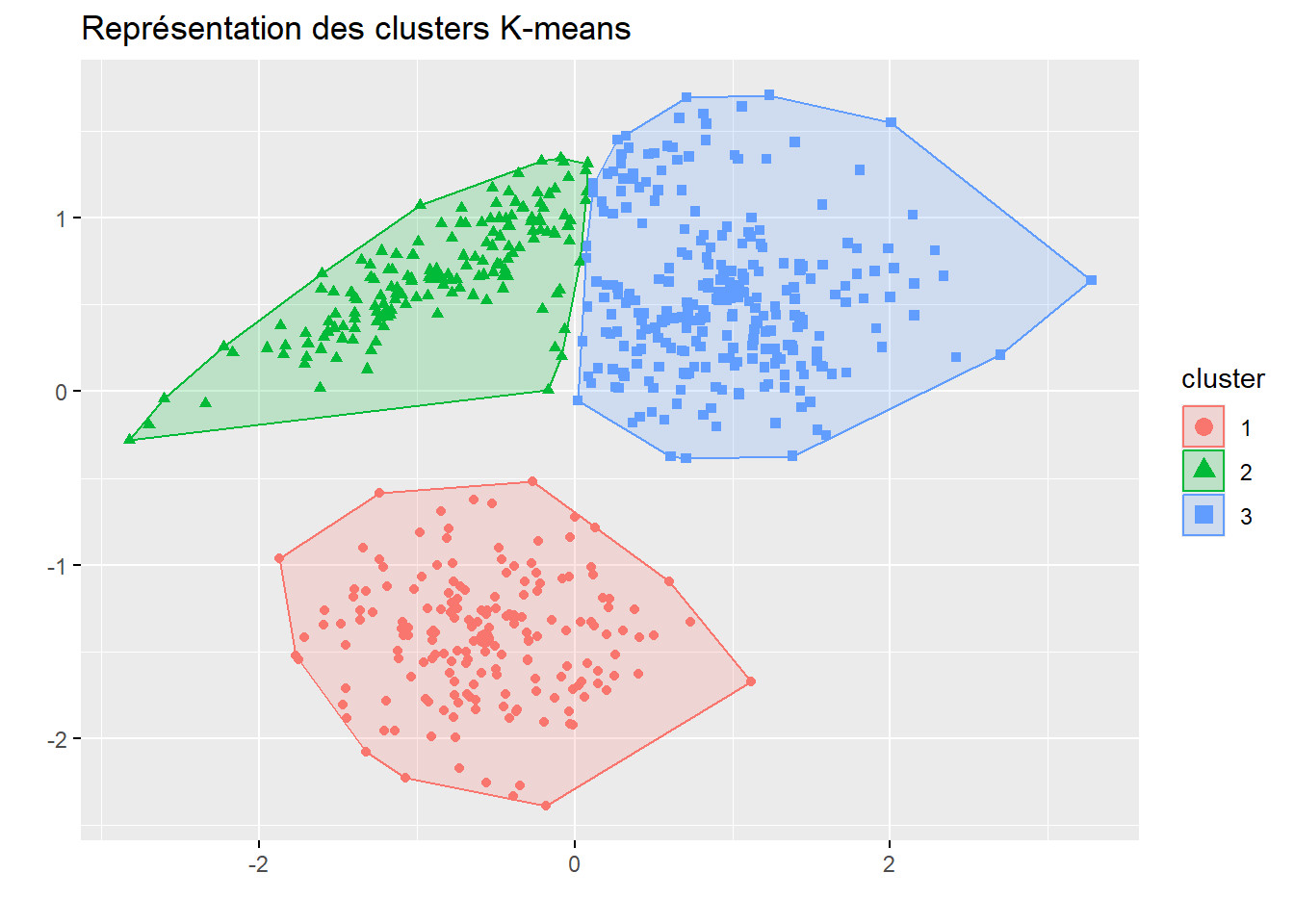
Cecie est un test
Les références
Flynt, Abby, et Nema Dean. 2016. « A Survey of Popular R Packages for Cluster Analysis ». Journal of Educational and Behavioral Statistics 41 (2): 205‑25.